HPA e VPA - Autoscaler
Autoscaling deploy (Horizontal
PodeAutoscaling (HPA)Vertical)
AprenderCriar uma aplicação básica- Escalar a
automatizaraplicação usando Horizontal Pod Autoscaler (HPA)- Escalar a
criaçaplicaçãoeusandoexclusãoVertical Pod Autoscaler (HPA)- Teste de
PodsdesempenhoconformeusandoaodemandaLocust
Topologia do Laboratório:
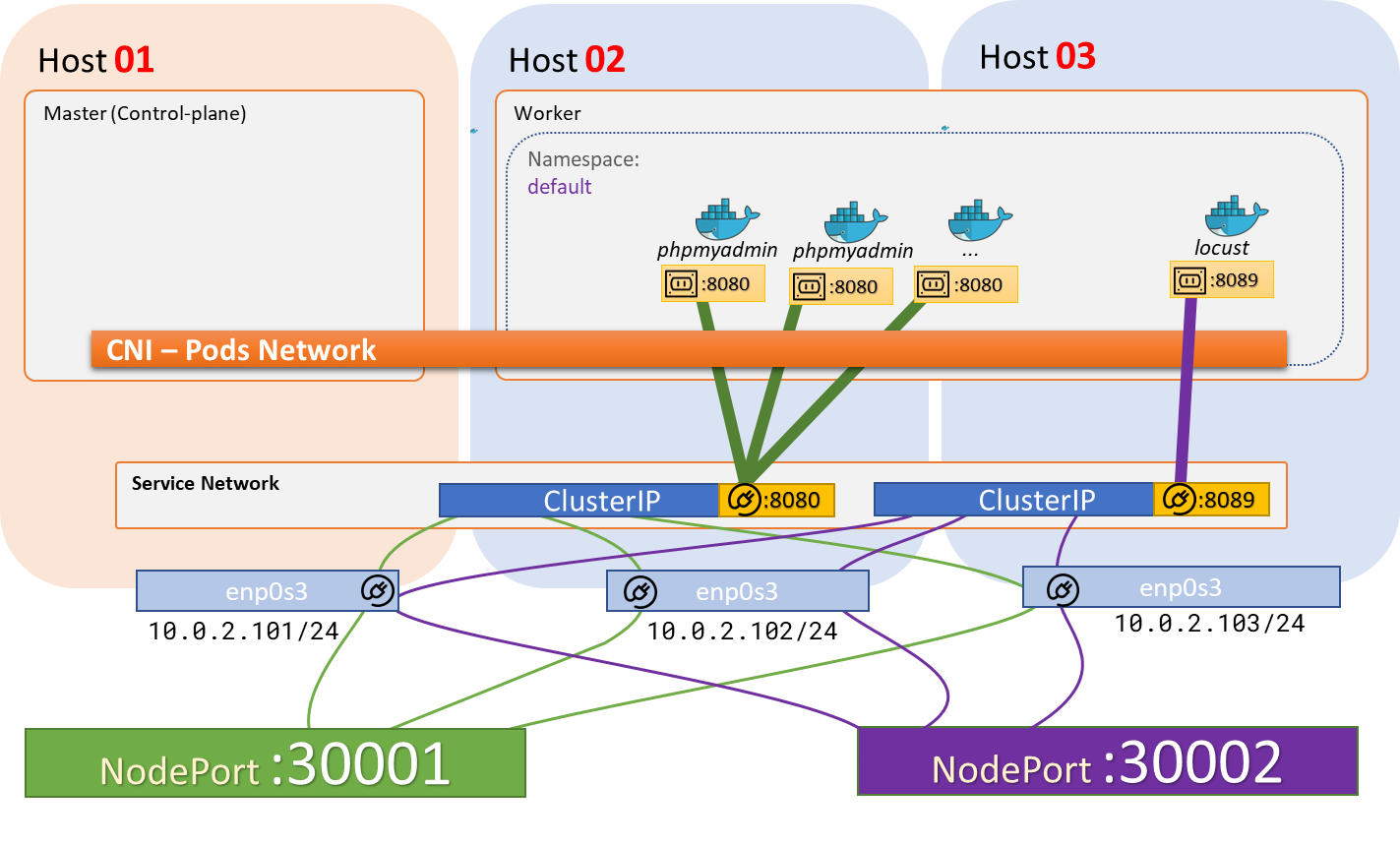
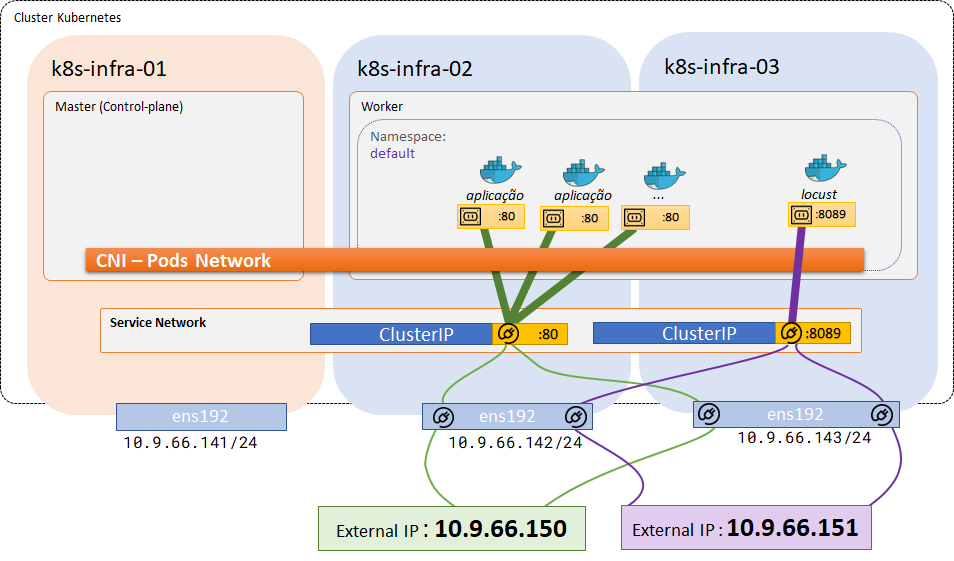
Estrutura inicial
1) Criando o diretório dos arquivos .yaml de deployment dos Pods.
mkdir ~/hpascaler && cd ~/hpascaler2) Instalando o serviço de coleta de métricas:
|
Antes de começarmos a explorar o Horizontal Pod Autoscaler (HPA), é essencial termos o Metrics Server instalado em nosso cluster Kubernetes. O Metrics Server é um agregador de métricas de recursos de sistema, que coleta métricas como uso de CPU e memória dos nós e pods no cluster. Essas métricas são vitais para o funcionamento do HPA, pois são usadas para determinar quando e como escalar os recursos.
O HPA utiliza métricas de uso de recursos para tomar decisões inteligentes sobre o escalonamento dos pods. Por exemplo, se a utilização da CPU de um pod exceder um determinado limite, o HPA pode decidir aumentar o número de réplicas desse pod. Da mesma forma, se a utilização da CPU for muito baixa, o HPA pode decidir reduzir o número de réplicas. Para fazer isso de forma eficaz, o HPA precisa ter acesso a métricas precisas e atualizadas, que são fornecidas pelo Metrics Server. |
Nota: Para aprendermos uma nova forma de instalarmos pacotes pré-definidos no kubernetes, vamos usar o gerenciador de pacotes HELM ( https://helm.sh/ ).
Instalar o Helm
curl -fsSL https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bashAdicionar o Repositório
helm repo add metrics-server https://kubernetes-sigs.github.io/metrics-server/Instalar o serviço de métricas
helm upgrade --install \
--set args={--kubelet-insecure-tls} metrics-server metrics-server/metrics-server \
--namespace kube-systemNota: Aguarde uns minutos até a criação dos Pods do serviço de métrica.
3) Verificar se tudo OK:
kubectl get pods -n kube-system | grep metrics-serverNota: Com o serviço de métricas funcionando, será possível usar o comando top para verificar o consumo de recurso pelos objetos:
kubectl top nodeskubectl top podsServidor de Aplicação
1) Antes de nos aprofundarmos no HPA, vamos criar um deployment simples usando qualquer imagem apenas para teste.
vi phpmyadmin.yaml# Deployment
apiVersion: apps/v1 # Versão da API que define um Deployment
kind: Deployment # Tipo de recurso que estamos definindo
metadata:
name: phpmyadmin # Nome do nosso Deployment
spec:
replicas: 1 # Número inicial de réplicas
selector:
matchLabels:
app: phpmyadmin # Label que identifica os pods deste Deployment
template:
metadata:
labels:
app: phpmyadmin # Label aplicada aos pods
spec:
containers:
- name: phpmyadmin # Nome do contêiner
image: bitnami/phpmyadmin # Imagem do contêiner
ports:
- containerPort: 80 # Porta exposta pelo contêiner
resources:
limits:
cpu: 400m # Limite de CPU
requests:
cpu: 100m # Requisição de CPU
#Service
---
apiVersion: v1
kind: Service
metadata:
name: phpmyadmin-service
spec:
ports:
- nodePort: 30001
port: 8080
protocol: TCP
targetPort: 8080
selector:
app: phpmyadmin
type: NodePort
2) Subir o deployment e o service do nginx:
kubectl apply -f phpmyadmin.yaml3) Verifique se o deploy foi finalizado e o POD está rodando (Running).
kubectl get podsHorizontal Pod Autoscaler (HPA)
Agora, com nosso deployment pronto, vamos dar o próximo passo na criação do nosso HPA. Neste exemplo, criamos um HPA que monitora a utilização da CPU do nosso nginx-deployment. O HPA se esforçará para manter a utilização da CPU em torno de 50%, ajustando o número de réplicas entre 3 e 10 conforme necessário.
1) Subir as especificações do HPA
vi hpa.yaml# Definição do HPA para o nginx-deployment
apiVersion: autoscaling/v2 # Versão da API que define um HPA
kind: HorizontalPodAutoscaler # Tipo de recurso que estamos definindo
metadata:
name: phpmyadmin-hpa # Nome do nosso HPA
spec:
scaleTargetRef:
apiVersion: apps/v1 # A versão da API do recurso alvo
kind: Deployment # O tipo de recurso alvo
name: phpmyadmin # O nome do recurso alvo
minReplicas: 1 # Número mínimo de réplicas
maxReplicas: 10 # Número máximo de réplicas
metrics:
- type: Resource # Tipo de métrica (recurso do sistema)
resource:
name: cpu # Nome da métrica (CPU neste caso)
target:
type: Utilization # Tipo de alvo (utilização)
averageUtilization: 50 # Valor alvo (50% de utilização)
behavior:
scaleUp:
stabilizationWindowSeconds: 0 # Período de estabilização para escalonamento para cima
scaleDown:
stabilizationWindowSeconds: 30 # Período de estabilização para escalonamento para baixo
2) Subir o HPA
kubectl apply -f hpa.yaml3) Verificar o serviço HPA se está ok
kubectl get hpaLocust (Stress Test)
Será instalado uma ferramenta para testes de stress chamada Locust ( https://locust.io/ ). Com ela vamos testar o stress do deployment do nginx para validarmos o HPA.
1) Arquivo locust.yaml
vi locust.yaml# ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: locust-config
data:
locustfile.py: |
from locust import HttpUser, task, between
class Fischer(HttpUser):
wait_time = between(1, 2)
@task(1)
def testar(self):
self.client.get("/")
self.client.get("/doc/html/index.html")
---
# Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: locust
spec:
replicas: 1
selector:
matchLabels:
app: locust
template:
metadata:
labels:
app: locust
spec:
containers:
- name: locust
image: locustio/locust
command: ["locust", "-f", "/etc/locust/locustfile.py"]
volumeMounts:
- name: locust-config
mountPath: /etc/locust
volumes:
- name: locust-config
configMap:
name: locust-config
---
# Service
apiVersion: v1
kind: Service
metadata:
name: locust-service
spec:
ports:
- nodePort: 30002
port: 8089
protocol: TCP
targetPort: 8089
selector:
app: locust
type: NodePort
2) Subir o deployment do serviço locust
kubectl apply -f locust.yaml3) Verifique se o deploy foi finalizado e o POD está rodando (Running).
kubectl get pods4) Fazer o teste usando o Firefox do ORC-Server.
Nota: Antes de abrir o navegado para o teste, deixe o comando abaixo rodando para acompanhar a criação dos Pods.
A opção -w ficará observando as mudanças (watching)
kubectl get deploy/phpmyadmin -w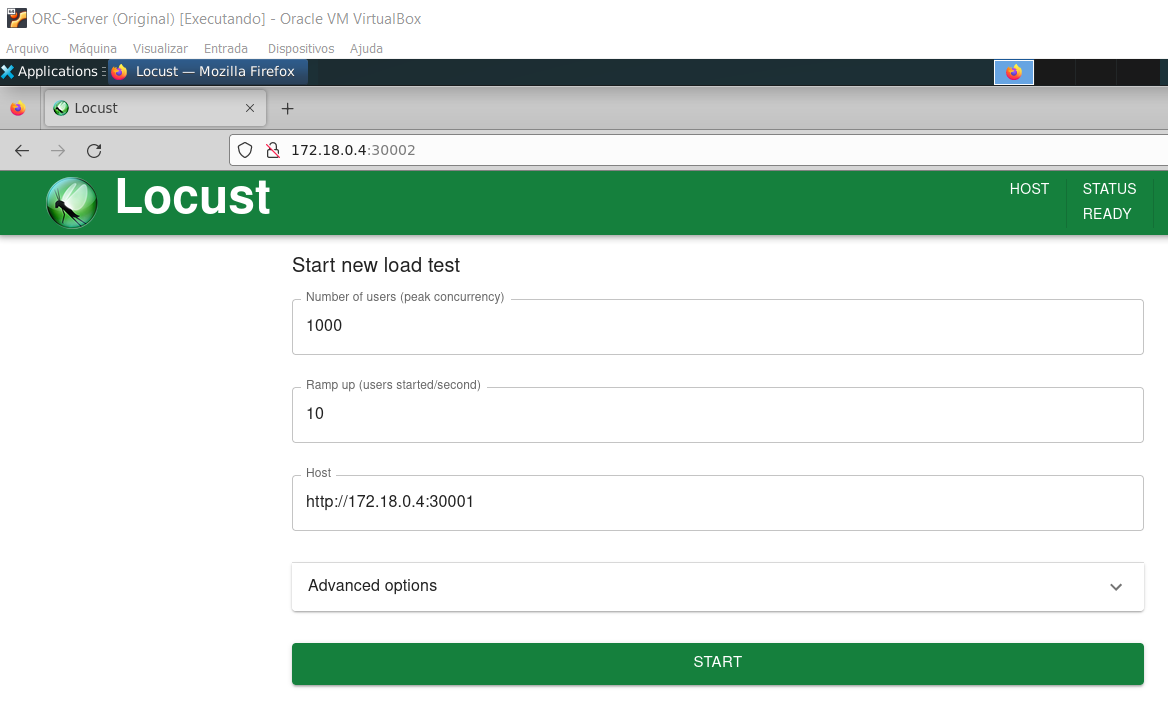
- Máximo de usuários simultâneos: 1000
- Incremento de 10 em 10.
- Host: http://172.18.0.4:30001 (serviço do PHPmyadmin).
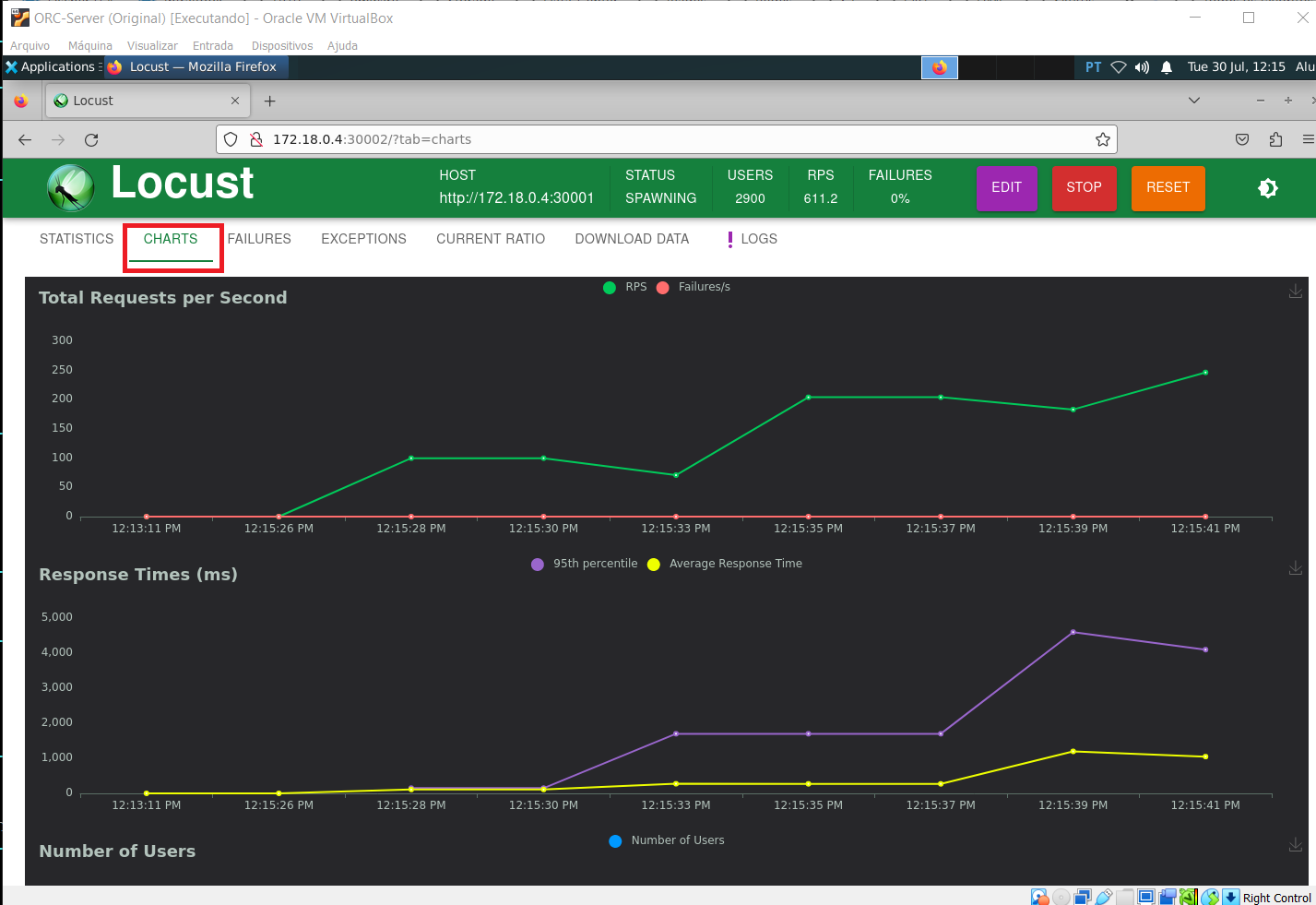
Atenção: Após a validação dos testes, pare a geração de tráfego de stress clicando em "STOP". Você também poderá excluir o deployment do locust. kubectl delete -f locust.yaml
Responda a pergunta 01 do laboratório.
Perguntas do Laboratório:
- (teórica) Qual a função do Horizontal Pod Autoscaler (HPA) no Kubernetes?